使用fiddler抓包的时候经常一下子显示很多的记录,看的眼花缭乱,需要这时候需要使用过滤条件来帮助你,一般常用的有三种过滤条件:
1.域名过滤,只显示特定域名的记录:

*.baidu.com表示所有的百度二级域名会话;*baidu.com表示一级域名+二级域名的会话。设置好了后一定要点击Actions生效;
2.类型过滤,一般对各种图片、CSS、JS这类的静态素材也不需要看的情况下,直接全部过滤掉
.*\.(bmp|css|js|gif|ico|jp?g|png|swf|woff)

需要过滤多少自己直接加入就好了
3.根据返回状态码,比如只想显示200的状态,其他的不显示

4.左侧添加请求时间列或其它列,右键表格的title。
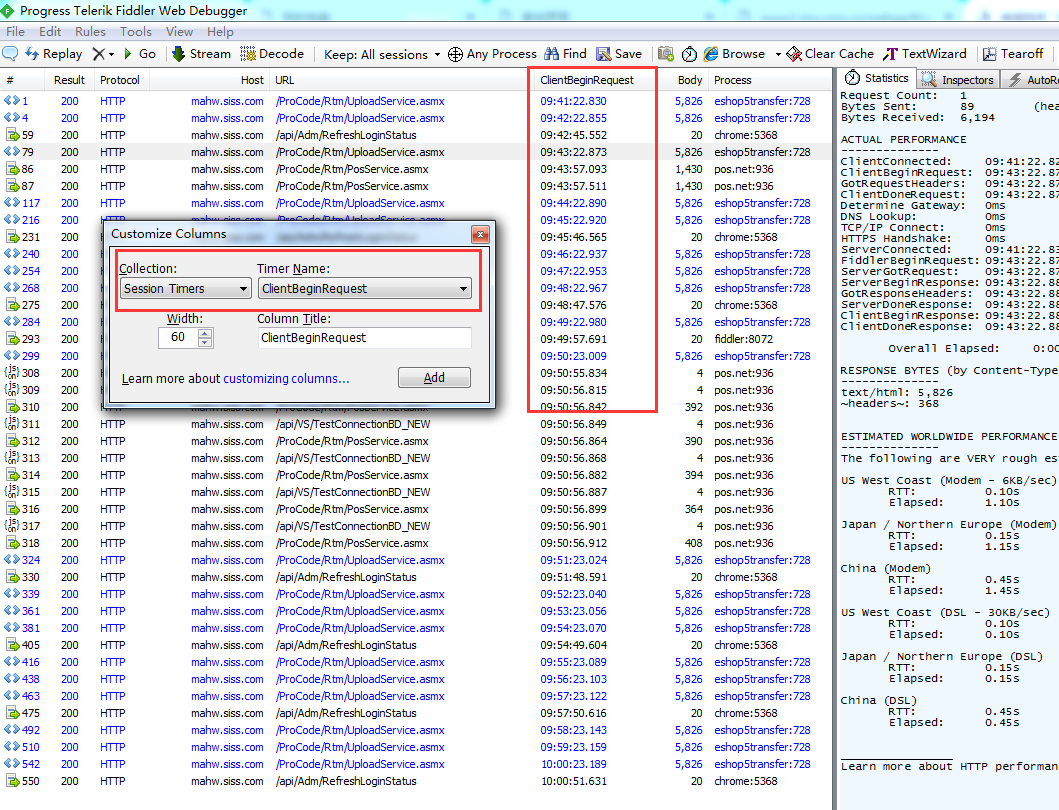
5.左侧按某列过滤出请求列表,右键表格的title。
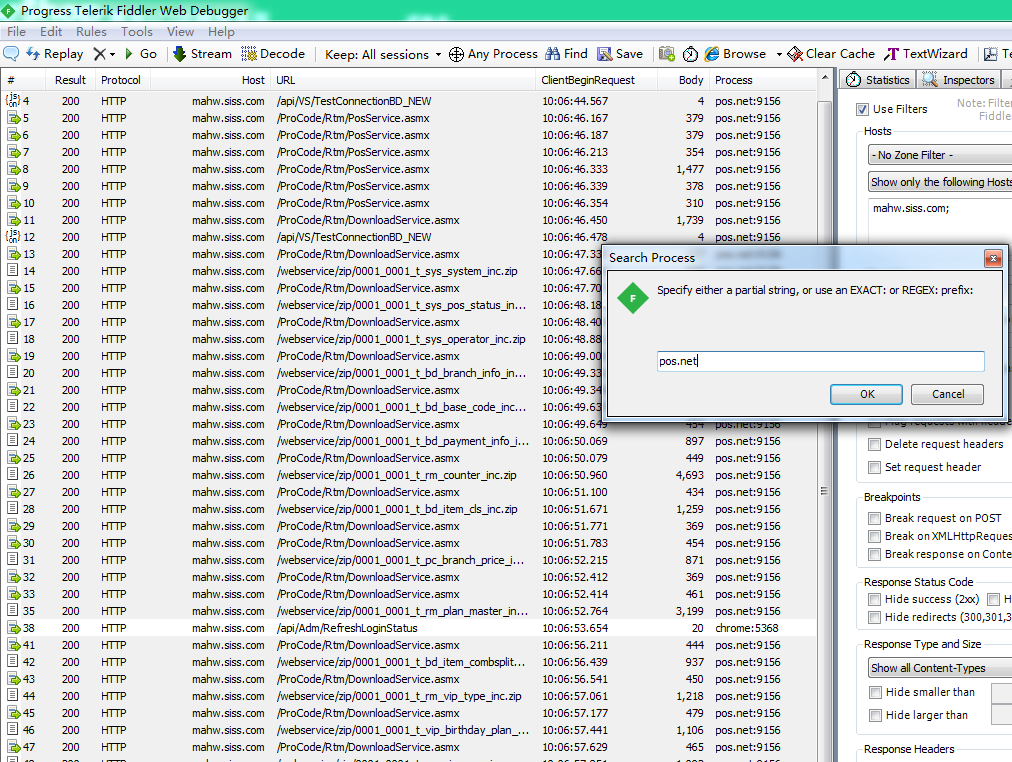
**************转摘:https://www.cnblogs.com/sunny-sl/p/6542375.html